{kind=link}

lecture13
2024-02-27
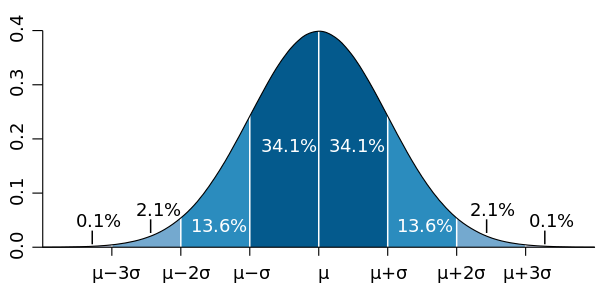
Quantifying the shape of the normal distribution
Median, quartiles
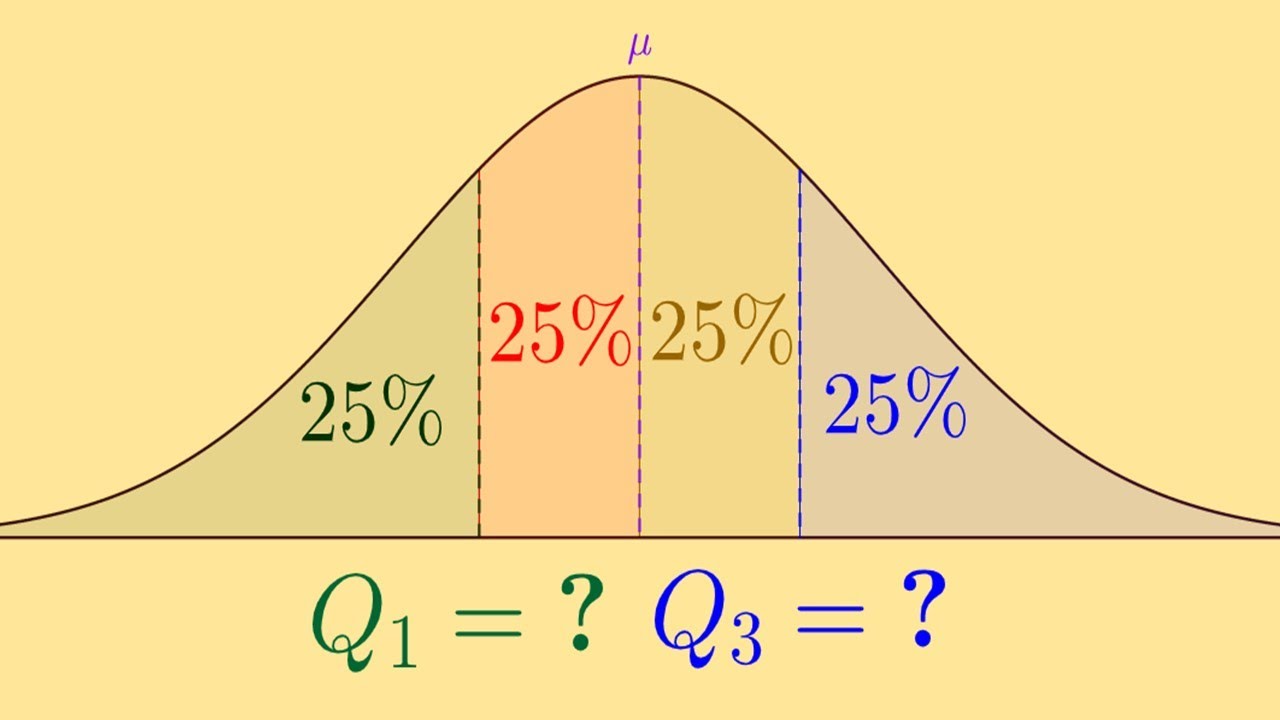
quartiles divide the probability / distribution area into 4 quarters, a more general way is called quantile (note the spelling!)
Quantiles tell us about the distribution shape
Quartiles (4)
Deciles (10)
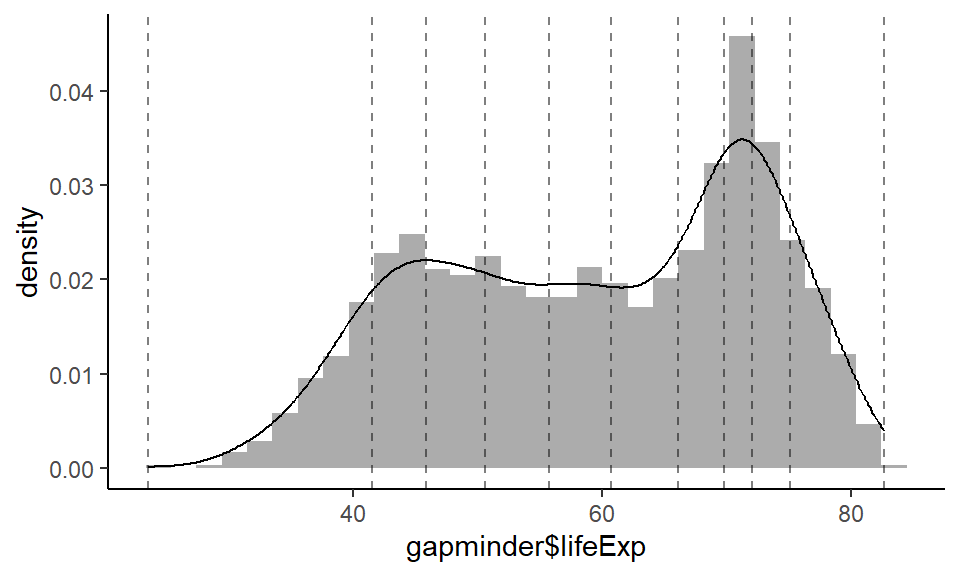
quantiles are cut points dividing the range of a probability distribution into continuous intervals with equal probabilities. Source: Wikipedia
probability distribution = geom_density plot. Hence quantiles divide the range to make equal area under the geom_density curve
Q-Q plot enables comparison of distribution shapes
If they fall along the line, then it is normal.
Normal distribution
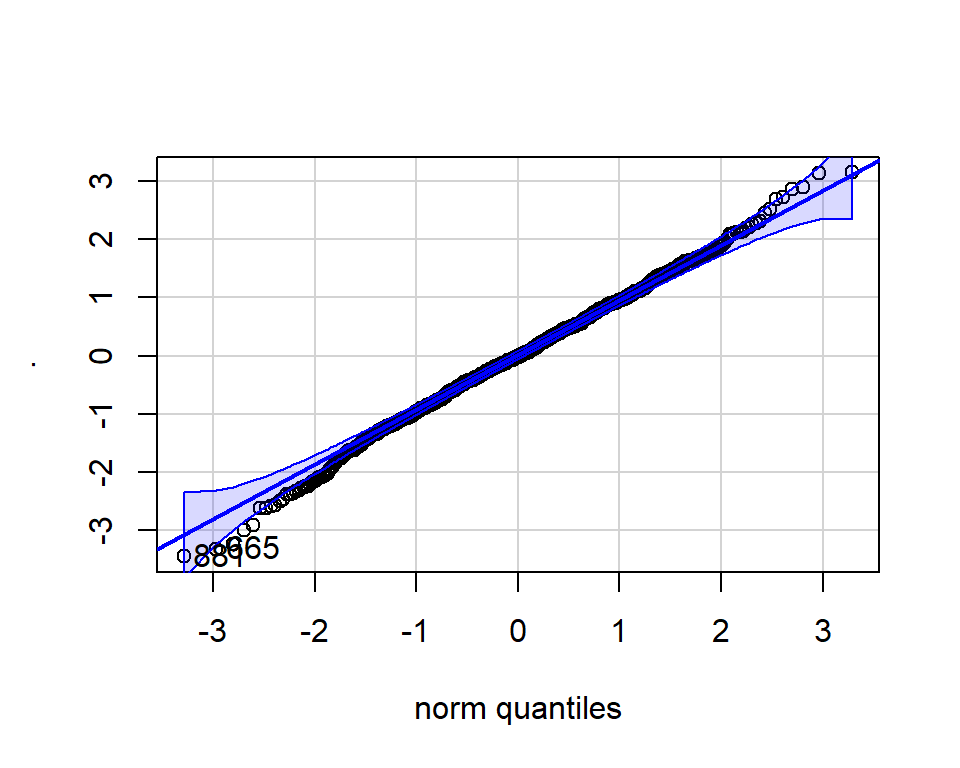
[1] 881 665Non-normal distribution
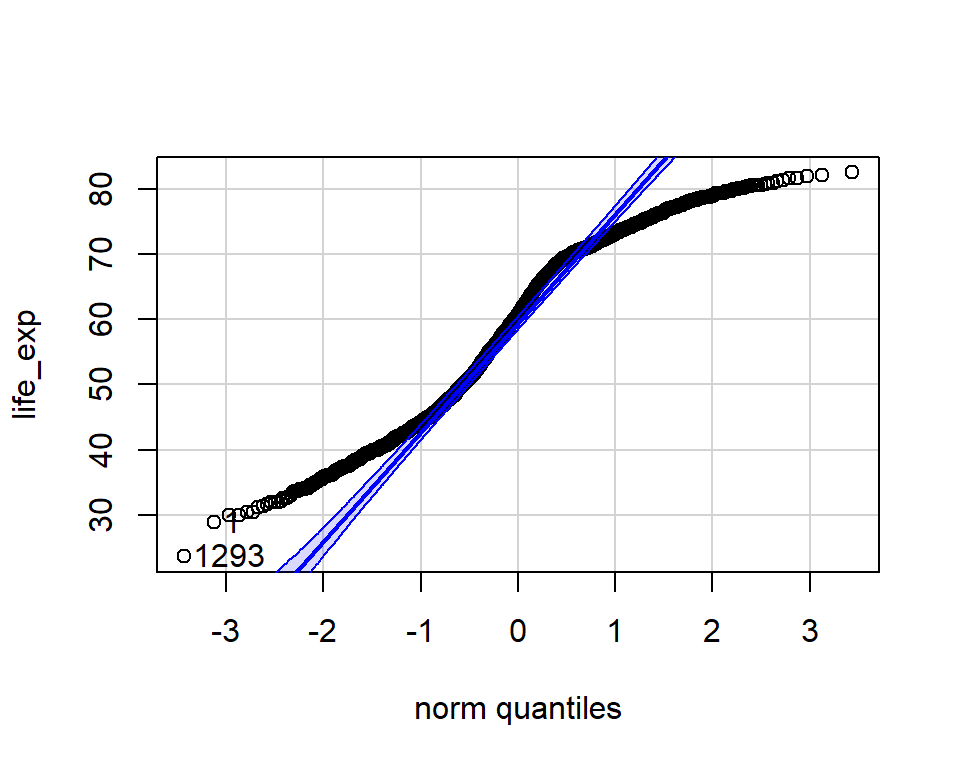
[1] 1293 1What data can test the smoking hypothesis?
2d data
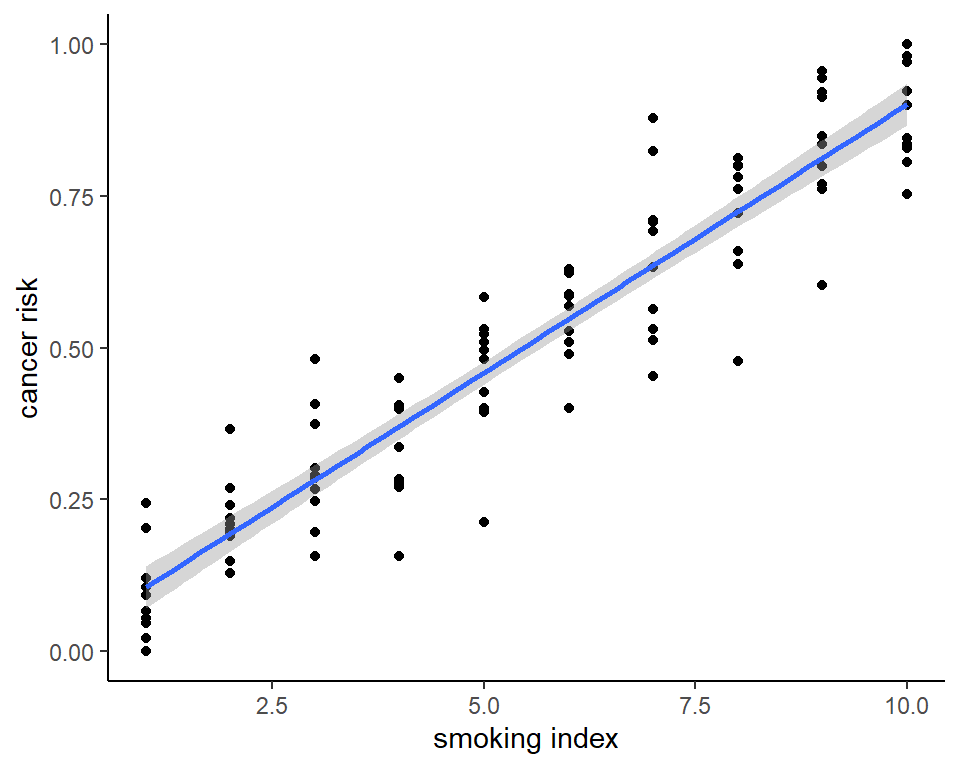
Correlation
Regression (linear/non-linear)
1D data

- t-test
t-test is calculating difference in means / spread around mean
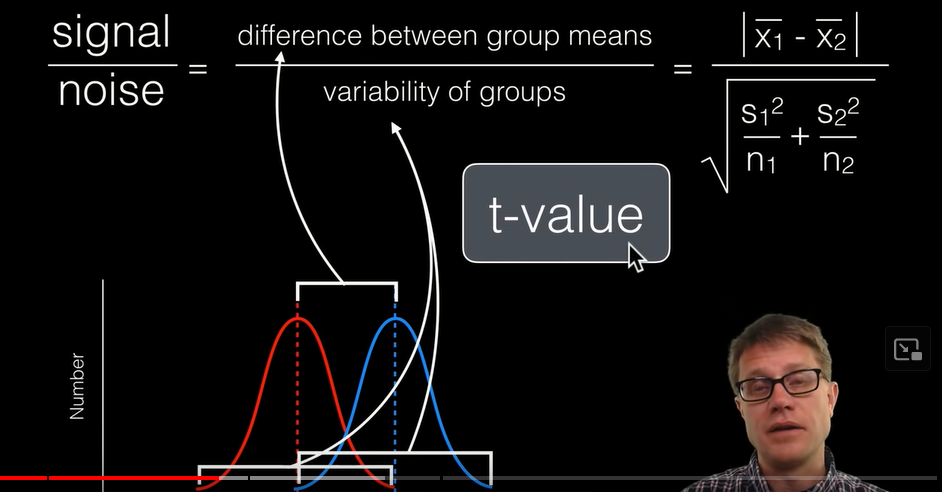
Watch full video here: “Student’s t-test” : Bozeman science/youtube