lecture 17: t-test and bootstrapping
2024-03-21
Difference of mean between samples
2 samples = t-test
more samples = ANOVA
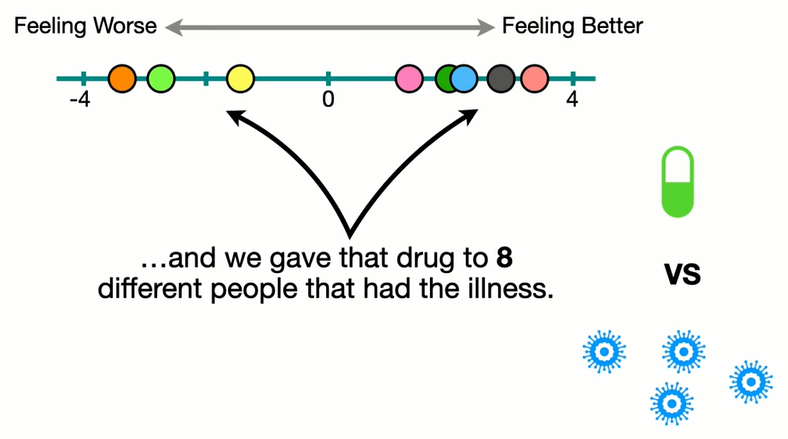
Sampling from a population
Population

Sample

Re-sampling = shuffling within the sample (w replacement)
Sample
Bootstrapped sample (re-sampling, with replacement)
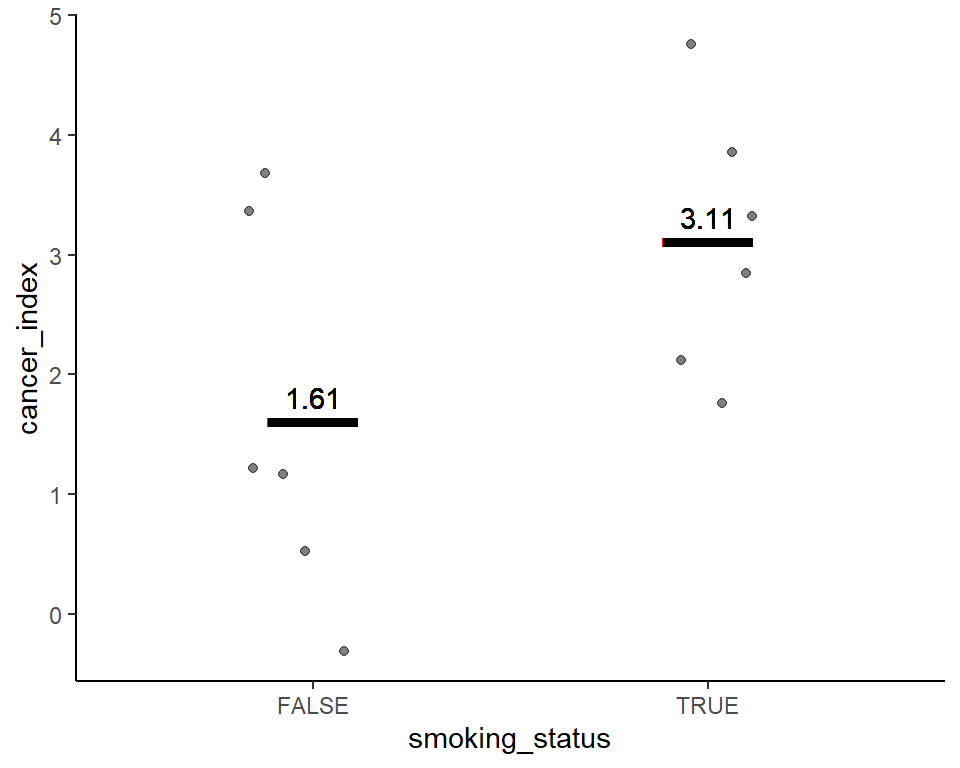
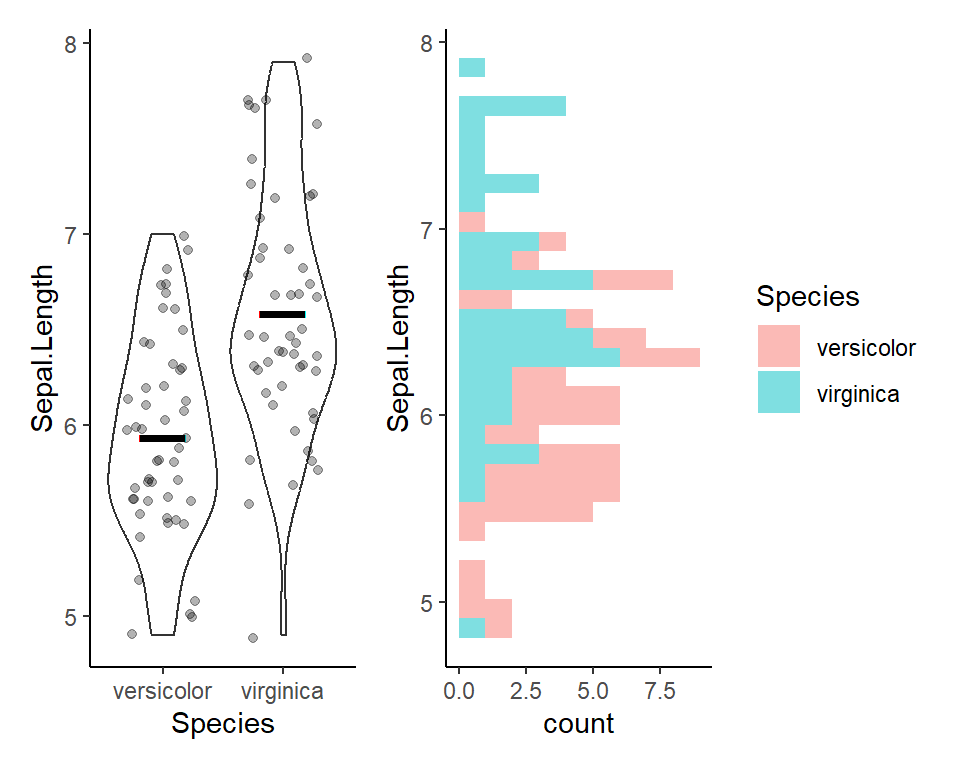
Dataset for t-testing

Visualize before 2-sample t-test
Here’s a plot outlining the data to use for t-test
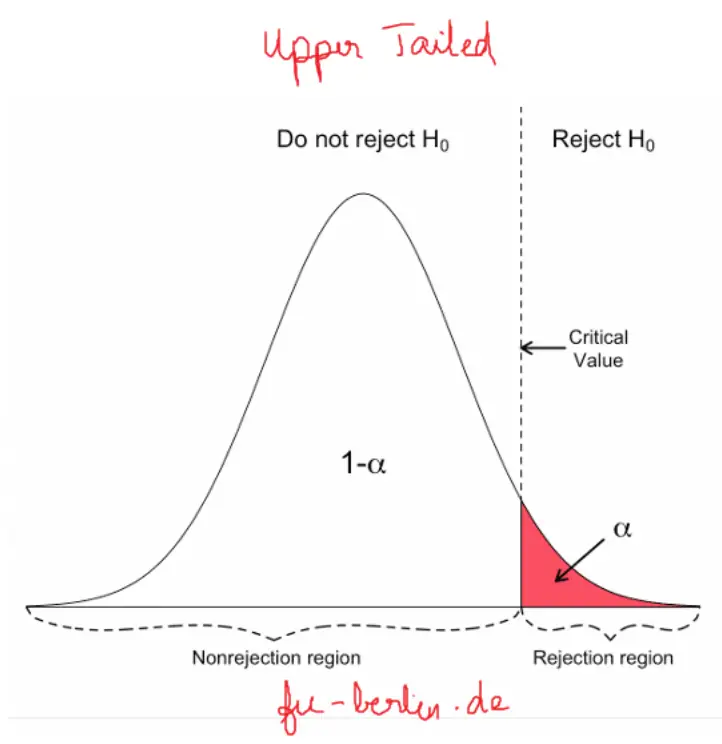
What is p-value?
p-value is the probability that the observed difference of means (or more extreme) can occur by chance if the NULL hypothesis is TRUE
This is calculated by
plotting a t-distribution around the null hypothesis mean difference (typically 0)
mark the observed mean difference
Find the tail of the distribution beyond the observed value
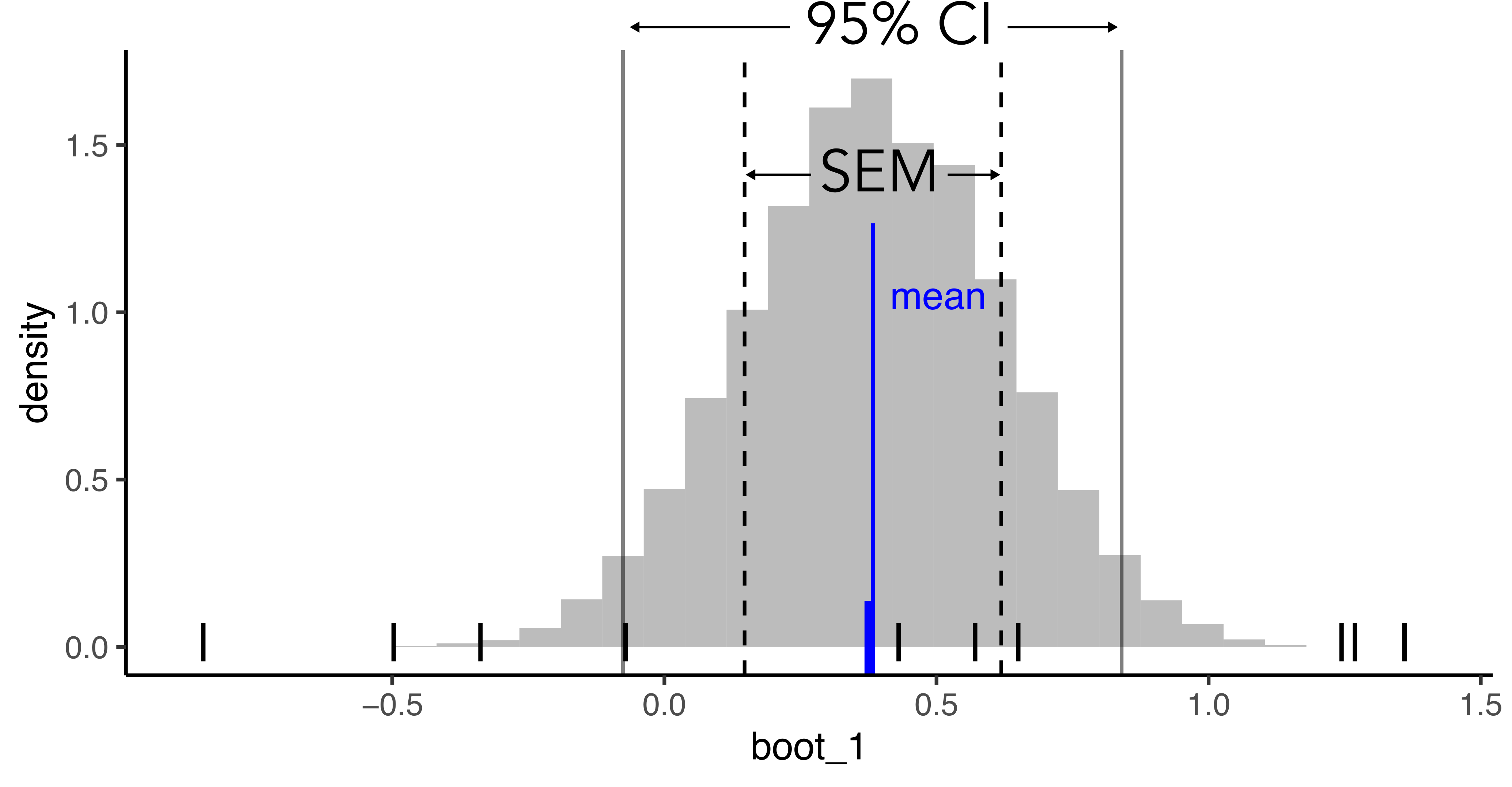
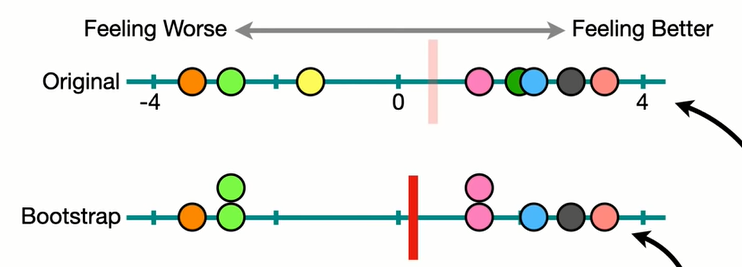
Bootstrapping to understand t-test better
Bootstrapping shows us the variability around the mean, by virtually repeating the experiment a bunch of times
For 1 sample, this is how the bootstrapped distribution looks like
Code
[1] -0.85 -0.50 -0.34 -0.07 0.43 0.57 0.65 1.25 1.27 1.36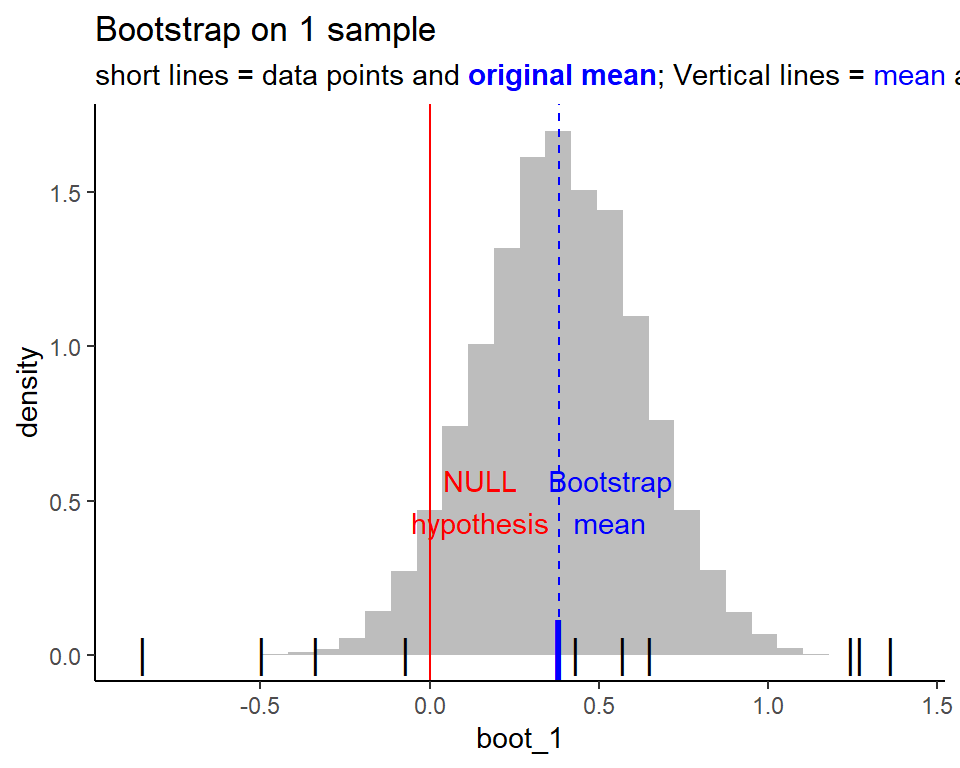
1-sample t-test w bootstrapping
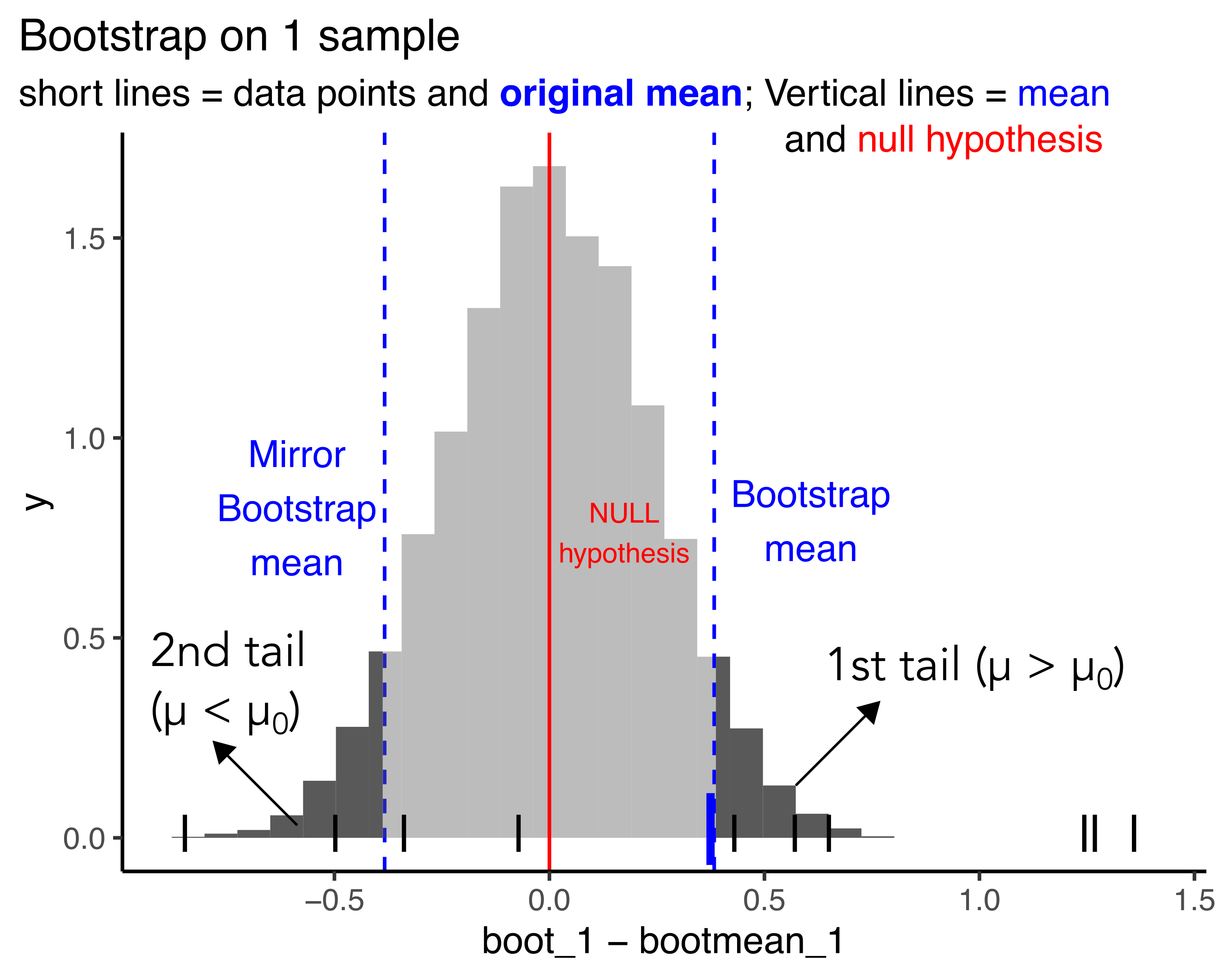
To get p-value from the bootstrapping, we need to find the area of the tails. To facilitate understanding, we shift the distribution to fit the null hypothesis. Which means, the mean of the distribution should be moved to the null hypothesis!
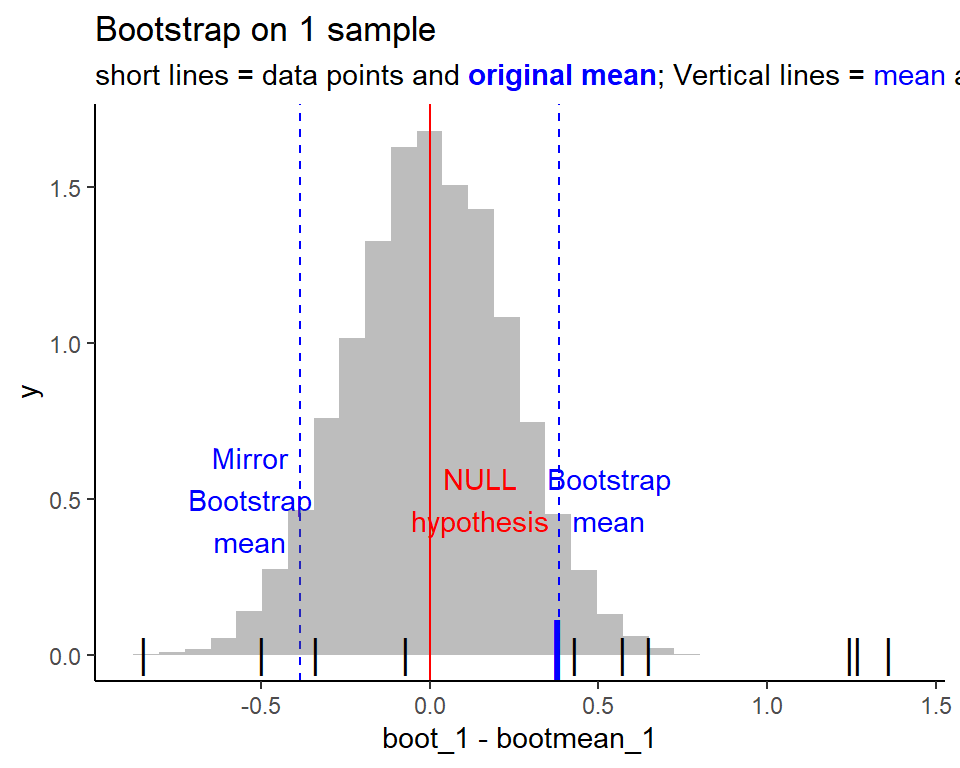
Showing the 2 tails
For a 2 tailed test, the p-value corresponds to the area under these two tails
Tail 1: \(\mu > \mu_0\)
Tail 2: \(\mu < \mu_0\)
Both tails: \(\mu != \mu_0\)
Exploring SEM, CI within bootstrap dist.
(SEM) Standard error of mean = std deviation of the bootstrapping distribution
(CI) 95% confidence interval => 95% of the mean distribution area lies within this range